Invented by O’NEILL; Allen

Keeping product pages up-to-date on eCommerce websites is a huge task. Online stores have thousands, sometimes millions, of products. Each product page holds key details—name, price, images, reviews, and more. These details change all the time. Making sure every page shows the right information can be hard, slow, and expensive. But what if computers could do this work almost automatically?
A recent patent application outlines a new way for computers to find, read, and update product pages on eCommerce sites. This blog post breaks down how it works, why it matters, and what makes it different from other ways of keeping online stores fresh.
Background and Market Context
Not long ago, if you wanted to see a product’s price or if it was in stock, you would walk into a store and check the shelf. Store managers, brand owners, and sellers would visit shops to make sure their products were set up right, priced fairly, and advertised well. They might spot-check prices, see if shelves were empty, or notice if a rival had a big sale.
Today, shopping has mostly moved online. Now, almost anything you could buy at a store can be ordered from your phone or computer. Big brands, small shops, and even new sellers all use eCommerce sites to reach buyers. Some sites, like Amazon, let many sellers list products on one marketplace. With so much happening online, keeping track of how products look and what they say on each page is harder than ever.
Why does this matter? If a product is listed with the wrong price, a buyer might get angry, or the company could lose money. If a product’s photo or description is wrong, it might not sell at all. And if rules change—like new safety laws or age limits—every page that sells those products must update fast or risk breaking the law.
But here’s the problem: eCommerce sites use many different designs, layouts, and ways to show information. A simple typo or website redesign can break tools that check or update product pages. Some companies use “screen scraping” tools—programs that read web pages like a person would, grabbing text and numbers. But these tools are fragile. If the website changes just a little, the tool can stop working or read the wrong thing.
So, what’s needed is a way for computers to find the right information on any product page, even if the design changes, and update it quickly and safely. This new patent application claims just such a method.

Scientific Rationale and Prior Art
To understand what’s new here, let’s look at how computers have handled this job in the past.
The old way is “screen scraping.” It’s like a robot with a checklist: “Find the big bold text at the top of the page—that’s the product name. Find the number next to the dollar sign—that’s the price.” Screen scraping tools use instructions called “queries” (like XPath or CSS selectors) to grab pieces of a web page. But if the website owner moves the price from the top to the bottom, or changes the text color, the tool gets lost. It might grab the wrong number or no number at all.
To fix this, developers must write new instructions for each website, and sometimes for every single type of page. This takes a lot of time and skill. And if the website changes again, the process repeats.
Some tools look for patterns in web pages, like “repeating boxes” that list products in a grid. Others might use a little artificial intelligence to guess what’s important. But even these methods need a lot of setup and checking.
In the past few years, some companies have tried to use machine learning (a kind of computer learning) to help. They show a computer many examples of product pages and tell it what to look for—like the product name or a review star. The computer learns patterns and can then try to find those parts on new pages. But even this can fail if the website uses brand-new layouts or hides information in tricky ways (like loading prices with JavaScript after the page loads).
So, the prior art—what came before—either relies on fragile, manual setup, or on machine learning that still needs a lot of checking and retraining. Most tools can’t easily handle pages that load information from many places (like images, prices, or reviews from different servers), or pages that look different on phones and computers. And few tools can spot changes in the law or rules and update pages to match.
That’s where the new patent application comes in. It claims a smarter, more flexible way for computers to read, understand, and update eCommerce product pages. Let’s see how it works.
Invention Description and Key Innovations
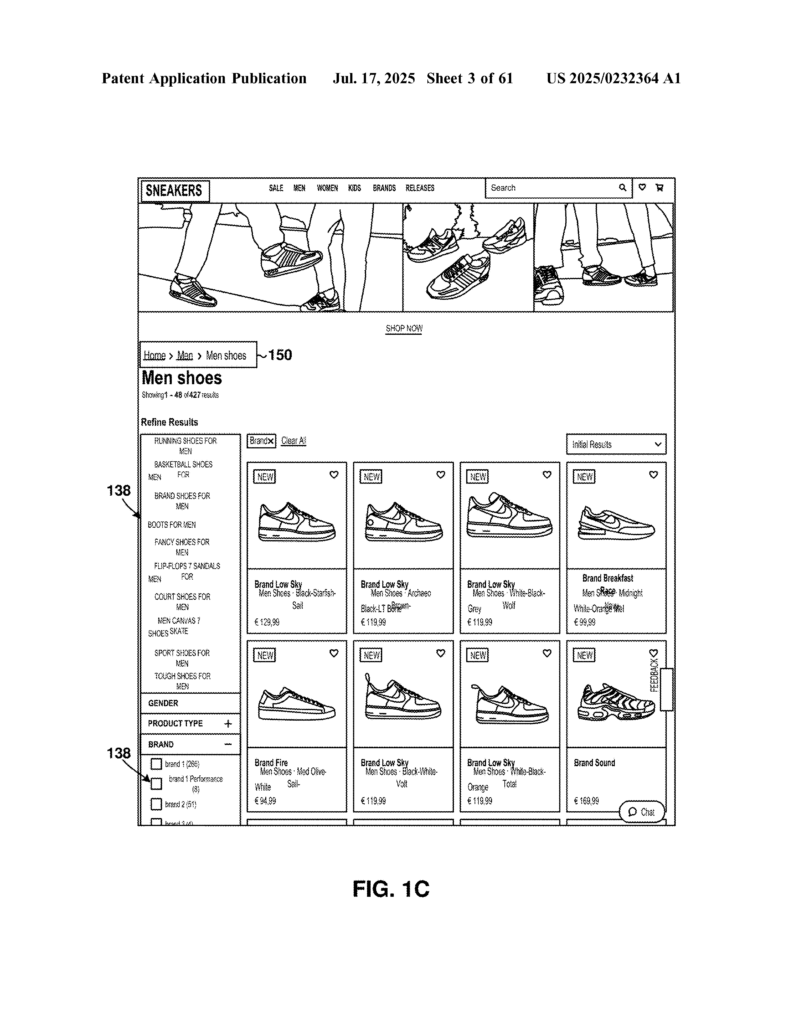
The invention describes a method for a computer (the “processor”) to update product pages on eCommerce websites with less risk of errors—even when the website’s look or layout changes. Here’s how it works, step by step, in simple terms.
1. Getting the Webpage
The computer gets the address (URL) of a product page. It then goes to the website and loads the page, just like a person would.
2. Building a “Map” of the Page
The computer turns the web page into a “structural model.” Think of this like a tree, where every part of the page (like the title, price, images, buttons) is a branch or a leaf. In programming, this is called the “DOM” (Document Object Model).
3. Checking for Similar Pages
Before doing anything else, the computer checks if it has already seen and worked on a page that looks the same. If so, it can use what it learned before, saving time.
4. Segmenting the Page
If this page is new (or different), the computer breaks it into parts—this is called “segmenting.” It looks for “anchor points”—special spots like the product name, price, or main image. It does this by looking at things like:
- What stands out visually (biggest or boldest text, bright colors, pictures)
- Where things are on the page (top, middle, side)
- How close parts are to each other (the price is usually near the name)
- Special symbols ($, €, %, etc.)
- Patterns that repeat (like lists of products in a grid)

5. Extracting Product Information
Once the computer has found the right spots, it grabs the information—like the product name, price, reviews, and more.
6. Updating the Page or Taking Action
With the new information, the computer can update the page, create a report, or even send alerts if something seems off (like a price that’s too low or a product that’s out of stock).
7. Handling Dynamic Content
Some pages load extra data after the main page appears—like prices loaded by JavaScript. The computer is smart enough to watch for these changes and grab the right data, even if it arrives late.
8. Machine Learning
The system can use machine learning in several ways:
- It can learn from lots of page layouts, so it gets better at finding the right spots on new pages.
- It can compare images and text, making sure the product image matches the description.
- It can adjust to new languages, currencies, or tricky cases (like fake products).
9. Quality Checks and Alerts
The computer double-checks its work by loading the same page several times, possibly from different places or with different devices. If the information is not the same each time, it can raise a red flag—maybe the site is trying to block automation, or there’s a bug.
10. Working Across Many Websites
The invention can build a “map” (taxonomy) of all products on a site, or even compare products across different sites. This helps sellers track how their products appear on many stores, find mistakes, or spot counterfeit goods.
11. Legal and Compliance Checks
If a product shouldn’t be sold in certain regions, or needs special warnings, the system can check that the pages have the right legal information. If not, it can send alerts or even pull the product from sale.
What Makes This Approach Special?
Most scraping tools break when the website changes. This invention uses a mix of rules, visual clues, and machine learning to “see” what parts of the page are important, even when layouts change. It keeps learning from new examples. It can handle different devices (phone, desktop, audio) and languages. It can tell if data is loaded dynamically. It can check for legal compliance and help stop the sale of fake goods. It can even work together with marketing or stock systems to change prices or stock automatically.
It is also designed to be efficient—using less computer power by only loading the important parts of a page, and skipping things it doesn’t need.
Actionable Takeaways:
- If you run an eCommerce site, tools like this can help keep your product pages accurate, up-to-date, and legally safe.
- If you’re a brand owner, you can track how your products appear across many online stores, spot mistakes or fake listings, and act fast.
- If you’re a developer, this patent describes a flexible way to build smarter, more reliable web data tools—mixing rules, visual analysis, and machine learning for better results.
Conclusion
Updating product pages on eCommerce websites is more important—and harder—than ever. Old tools that scrape pages can break easily and miss important information. The new system described in this patent application is much smarter. It can find, read, and update product details on almost any eCommerce page, even as websites change. It uses visual clues, patterns, and machine learning to work faster and more reliably. It can help sellers, brands, and website owners keep their information right, their customers happy, and their businesses safe.
As online shopping keeps growing, tools like this will be key for anyone who wants to stay ahead. If your business depends on accurate, up-to-date product pages, it’s time to look at smarter ways to manage your data—and this invention shows what’s possible.
Click here https://ppubs.uspto.gov/pubwebapp/ and search 20250232364.